Context Engineering: Новая прафесія на скрыжаванні інтэлекту і інфармацыі
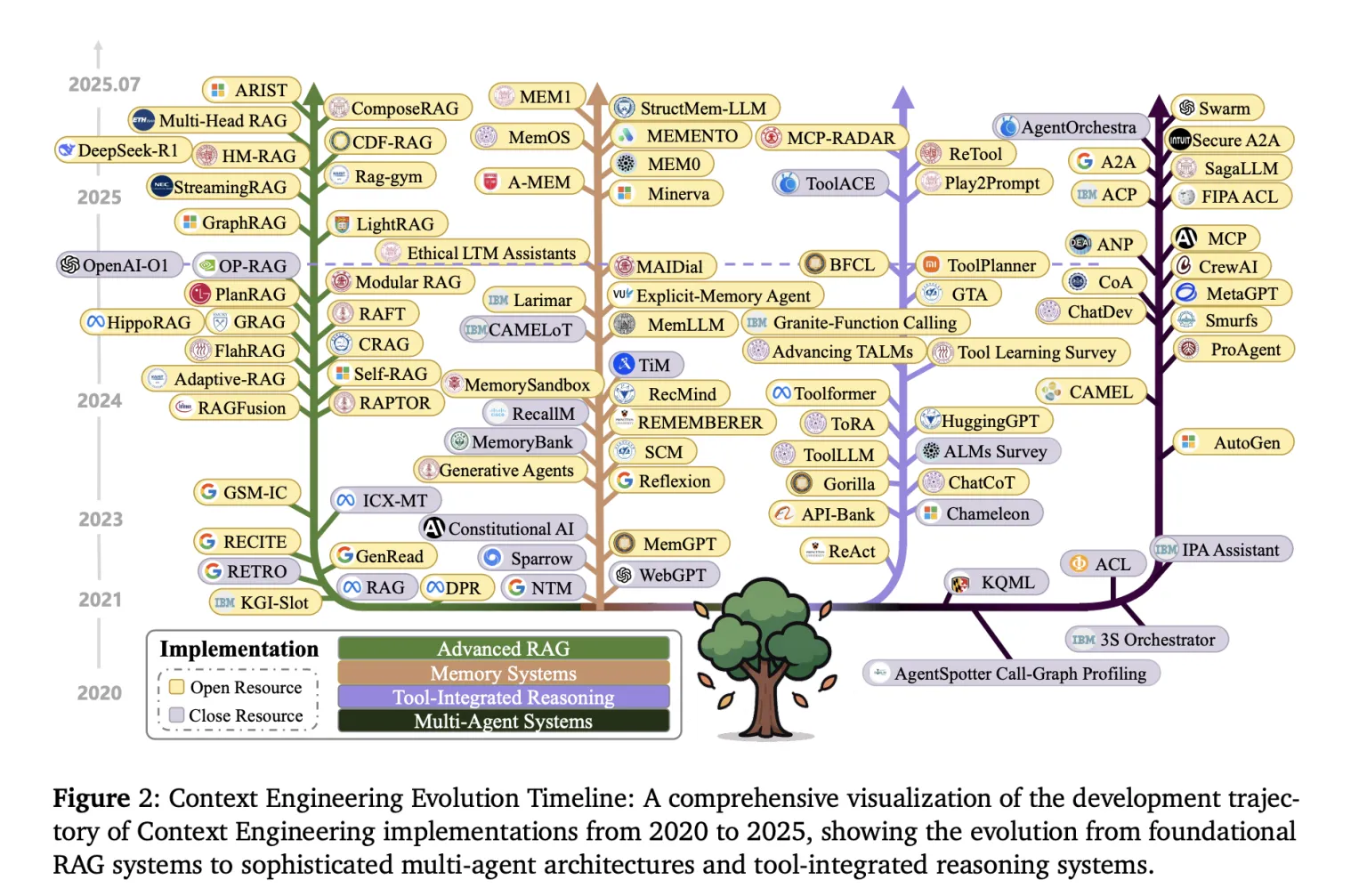
Гэты артыкул - абагульненне некалькіх артыкулаў пра новы напрамак, які ўжо зараз ператвараецца у новую прафесію , якая з часам будзе вельмі запатрабаванай.
Context Engineering: Новая прафесія на скрыжаванні інтэлекту і інфармацыі
1. Чаму гэта важна?
Сённяшнія LLMs — гэта не проста тэкставыя генератары. Гэта магутныя сістэмы, здольныя:
- аналізаваць інфармацыю;
- будаваць лагічныя ланцужкі;
- прымаць рашэнні;
- падтрымліваць складаныя дыялогі.
Аднак іх здольнасці абмяжоўваюцца толькі тым, які кантэкст яны атрымліваюць. І нават самая дасканалая мадэль будзе марнаваць свой патэнцыял, калі “не зразумее”, што ад яе патрабуецца.
Кантэкст — гэта не проста запыт. Гэта цэлае інфармацыйнае асяроддзе, у якім працуе ШІ: дакументы, прыклады, накіраванні, ранейшыя размовы, — усё, што ўплывае на разуменне і прыняцце рашэння. І тое, як мы ствараем і падаем гэты кантэкст, — вызначае эфектыўнасць усяго ўзаемадзеяння з мадэллю.
Так з’явілася цэлая галіна — context engineering. Яна вырасла з prompt engineering і ператварылася ў асобную прафесію, якая спалучае тэхналогіі, логіку і інфармацыйны дызайн. Гаворка ідзе пра сістэмны падыход да працы з кантэкстам: ад яго пошуку да кіравання ім у рэжыме рэальнага часу.
⸻
2. Аснова context engineering — што яна сабой уяўляе?
Калі prompt engineering — гэта пра тое, як сфармуляваць запыт, то context engineering — гэта пра стварэнне ўмоў для разумнага адказу. Гэта як не проста задаць пытанне, а даць чалавеку дакументы, факты, прыклады і мову, якой варта карыстацца.
Context engineering ахоплівае тры асноўныя кампаненты:
2.1. Context retrieval and generation
На першым этапе трэба знайсці і падаць мадэлі патрэбную інфармацыю:
- Prompt engineering — базавыя запыты і іх структура.
- In-context learning — метады накшталт zero-shot, few-shot, chain-of-thought, калі мадэль вучыцца на прыкладах унутры кантэксту.
- Retrieval знешніх ведаў — напрыклад, з баз дадзеных ці дакументаў (retrieval-augmented generation).
- Дынамічныя шаблоны — адаптыўныя запыты (напрыклад, CLEAR framework), якія змяняюцца ў залежнасці ад сітуацыі.
2.2. Context processing
Далей — апрацоўка інфармацыі:
- Працэсінг доўгіх паслядоўнасцей — мадэлі, здольныя працаваць з тэкстамі на тысячы токенаў (Mamba, LongNet).
- Самаўдасканаленне — мадэлі, што вучацца з уласных адказаў і карэктуюць кантэкст.
- Мультымадальнасць — камбінацыя тэксту, гуку, выяваў, табліц.
- Аптымізацыя ўвагі і памяці — тэхнікі сціску, sparsity, забывання непатрэбнага.
2.3. Context management
І, нарэшце, кіраванне кантэкстам у часе:
- Памяць: кароткатэрміновая (размова), доўгатэрміновая (біяграфія карыстальніка), знешняя (базы дадзеных).
- Context compression — аўтакодэры, рэкурэнтнае сцісканне.
- Paging — падзел кантэксту на старонкі з доступам да патрэбнай інфармацыі.
- Маштабаванае кіраванне — для складаных сцэнароў з некалькімі агентамі.
3. Як гэта працуе: архітэктурныя рашэнні
Context engineering ужо ўвасабляецца ў канкрэтныя тэхнічныя мадэлі і архітэктуры. Вось некалькі прыкладаў:
3.1. Retrieval-augmented generation (RAG)
Калі мадэль не мае патрэбнай інфармацыі — яна можа “запытаць” яе звонку. RAG дазваляе LLM:
- шукаць дадатковыя звесткі;
- выкарыстоўваць іх у рэжыме рэальнага часу;
- абапірацца на факты пры генерацыі адказу.
3.2. Сістэмы памяці
LLM з памяццю — гэта мадэль, што не “забывае”:
- можа весці працяглыя дыялогі;
- успамінае вашыя папярэднія пытанні;
- адаптуецца да вашых інтарэсаў (напрыклад, MemGPT).
3.3. Інструментальныя агенты (tools, agents)
Мадэль, што не толькі адказвае, але і дзейнічае:
- запускае код;
- шукае інфармацыю ў інтэрнэце;
- узаемадзейнічае з API.
3.4. Шматагентныя сістэмы
Некаторыя задачы патрабуюць каманды. Шматагентныя сістэмы:
- падзяляюць ролі;
- абменьваюцца кантэкстам;
- працуюць сінхронна для вырашэння складаных задач.
4. Што яшчэ не зроблена: асноўныя праблемы
Тэхналогія развіваецца імкліва, але ёсць і праблемы:
- Разрыў разумення і генерацыі — LLM можа зразумець складаны кантэкст, але не заўсёды здольны стварыць якасны вынік на яго аснове.
- Метрыкі ацэнкі — класічныя метрыкі (BLEU, ROUGE) недастатковыя для ацэнкі reasoning або кааперацыі агентаў.
- Мультымадальная інтэграцыя — цяжка аб’яднаць тэкст, гук, выявы, табліцы ў адзінны лагічны ланцуг.
- Бяспека і этыка — кантэкст можа быць скажоны, маніпулятыўны або прыватны.
5. Напрамкі будучыні: што чакае context engineering
Што будзе развівацца:
- Уніфікаваная тэорыя — фармалізацыя прынцыпаў context engineering.
- Новая генерацыя памяці — мадэлі, што памятаюць не толькі тэкст, але і сэнс.
- Поўная мультымадальная інтэграцыя — тэкст + відэа + аўдыё + графы.
- Лепшыя метады ацэнкі — метрыкі, што ўлічваюць логіку, паслядоўнасць, адаптыўнасць.
- Этычнае разгортванне — празрыстасць, тлумачальнасць, справядлівасць.
6. Рэзюмэ
Context engineering — гэта не проста новы трэнд. Гэта аснова новай хвалі штучнага інтэлекту:
- разумнага;
- адаптыўнага;
- карыснага;
- адказнага.
І калі вы працуеце з LLM, то хутчэй за ўсё — вы ўжо context engineer. Пытанне толькі ў тым, ці робіце вы гэта інтуітыўна — ці свядома і прафесійна.
Крыніцы
Каментары
(Каб даслаць каментар залагуйцеся ў свой уліковы запіс)